How to do distributed locking
by Martin Kleppmann我在 Redis 的官网上偶然发现了一个叫做 Redlock 的算法,恰好与我的书研究的一部分相关。这个算法自称能在 Redis 上实现容错的分布式锁(准确地说是租约[1]),并向研究分布式系统的人征求意见。看见这个算法,我出于本能地在脑海里敲响了警钟,所以我花了些时间来思考并且写下了这些笔记。
因为已经有十多个 Redlock 的实现了,并且我们不知道谁已经使用这个算法了。所以我认为值得把我的笔记公开分享出来。我不会深入探讨 Redis 的其他部分,因为那些已经在其他地方讨论过了。
在我深入 Redlock 的细节之前,首先要声明我十分喜欢 Redis,并且已经在生产环境中成功地使用过它了。我认为它非常适合在服务器之间共享一些频繁变化的数据,而且偶尔丢失部分数据也无关紧要。例如,维护每个 IP 地址的请求计数器(出于限制的目的)和每个用户 ID 的不同 IP 地址集(用于滥用的检测)。
然而,Redis 已经逐渐进入有强一致性和持久性特点的数据管理领域,这让我很担心,因为这不是 Redis 设计的初衷。有争议的是,分布式锁也属于这一领域。让我们更详细地研究一下。
你用锁来干什么
锁的目的是用来保证当多个节点尝试做相同的工作时,实际上只有一个节点能够完成(至少在同一时刻只有一个)。这个工作可能是将一些数据写入一个共享的存储系统、完成一些计算、调用一些外部的 API 或者其他类似的工作。宏观上来看,有两个原因来说明为什么在一个分布式应用中需要一个锁:效率和正确性[2]。为了区别这些情况,可以继续往下看当锁失效的时候会发生什么:
- 效率:使用锁可以避免做不必要的重复工作(例如一些代价昂贵的计算)。如果锁失效时两个节点做相同的工作,结果会是成本略有增加(最后要比其他方式多给 AWS 支付5美分)或带来小小的不便(用户可能会收到两个相同的邮件通知)。
- 正确性:使用锁可以避免并发进程相互影响最终搞乱系统的状态。如果锁失效时两个节点同时处理同一部分数据,结果可能造成文件损坏、数据丢失、永久的不一致性、给病人服用了错误剂量的药物或其他严重的问题。
以上两点都是需要锁的有效情况,但是你需要十分明确你是在处理哪一种情况。
我的观点是:如果只是出于提高效率的目的,那么没有必要承担 Redlock 的成本和复杂的逻辑,你没必要运行5台 Redis 实例来检查是否有大多数都获得了锁。你最好只启动一个 Redis 实例,或是当主节点崩溃时异步复制到从节点。
如果你使用单个 Redis 实例,在 Redis 节点断电时当然会丢失一些锁,同时可能会出现一些问题。但是如果你使用这些锁来优化效率的话,其实节点的崩溃不会频繁发生,这也没什么大不了。这个“没什么大不了”的正是 Redis 的特点。至少当你依赖于一个 Redis 实例的时候,每个查看系统的人都心知肚明这些锁不太严谨,仅用于不太关键的目的。
另一方面,具有5个副本和多数投票的 Redis 算法乍一看似乎适用于对正确性要求很高的情况。在接下来的几个章节中我将论证它不适用于这个目的。文章的其余部分假定你的锁对保障系统的正确性至关重要,并且两个节点持有同一个锁是严重的错误。
使用锁来保护资源
先把 Redlock 的具体应用放在一边,讨论一下通常一个分布式锁是如何使用的(不依赖于某个加锁算法)。要牢记住分布式系统中的锁和多线程应用中的互斥量不一样,这一点很重要。由于不同的节点和网络都能以各种奇葩的方式发生故障,所以它更让人觉得可怕。
假如你有一个应用,其中客户端需要更新共享存储中的文件(如 HDFS 或 S3)。一个客户端首先获得一个锁,然后读取这个文件,作出一个修改,将改动写回,最终释放这个锁。这个锁避免两个客户端并发执行读-修改-写这一系列动作以防丢失更新。代码可能像下面这样:
// THIS CODE IS BROKEN
function writeData(filename, data) {
var lock = lockService.acquireLock(filename);
if (!lock) {
throw "Failed to acquire lock";
}
try {
var file = storage.readFile(filename);
var updated = updateContents(file, data);
storage.writeFile(filename, updated);
} finally {
lock.release();
}
}
不幸的是,即使你写的锁看起来非常完美,上面的代码也不是安全的。下面的图展示了数据是怎么被破坏的:
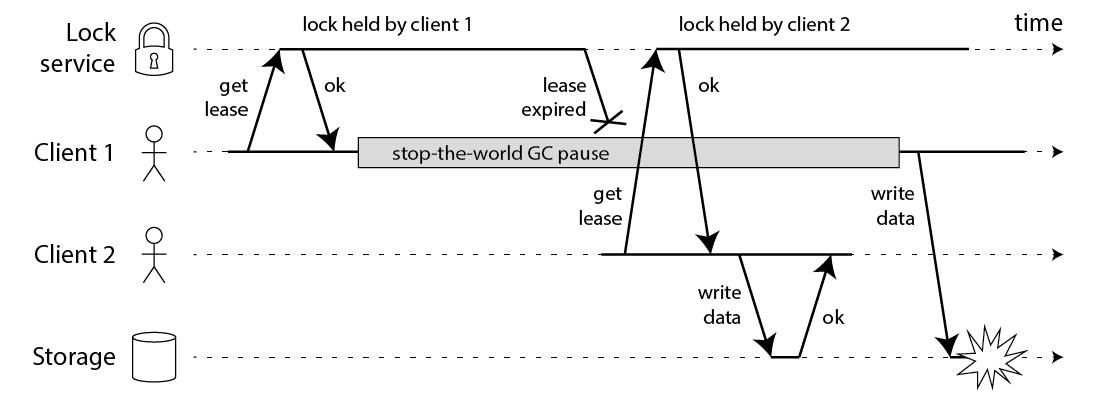
在这个例子里,持有锁的客户端在持有锁的过程中暂停了很长的时间——如 GC。为锁设置超时时间(也就是租约)总是一个好主意(否则,崩溃的客户端可能会永远持有一个锁,并且永远不会释放)。然而,如果 GC 暂停的时间持续地比租约到期的时间更久,而且客户端没有意识到锁已经过期了,它会继续向后执行一些不安全的操作。
这个 Bug 不是理论上的:HBASE 经常有这个问题[3,4]。通常来说,GC 停顿非常短,但是已经知道的是 “stop-the-world” GC 会停顿几分钟[5]——已经足够等到租约过期了。即使是所谓的“并发”垃圾收集器,如 HotSpot 的 CMS,也不能完全与应用程序代码并行运行——甚至它们需要不时地停止运行[6]。
不能通过在写回存储之前插入对锁的过期检查来修复这个问题。请记住,GC 以在任何时间暂停正在运行的线程,包括对你最不利的时间点(在最后一次检查和写入操作之间)。
如果你用的语言没有长时间停顿的话,也有许多其他的原因让你的进程暂停。也许你的线程尝试访问还没有加载进内存的地址,那么会发生一个页错误直到页从硬盘加载进来。也许你的硬盘实际上是 EBS,在 Amazon 拥挤的网络上读取变量不经意间变成了同步请求。也许有许多其他进程在竞争 CPU,而你遇到了调度器树中一个黑节点。也许有人突然向进程发送了 SIGSTOP。结果都是你的进程会被暂停。
如果你仍不相信我关于进程暂停的观点,那么可以改成考虑文件在写入请求在到达存储服务之前会遇到网络延迟的情况。像以太网和 IP 之类的分组网络可能会任意地延迟包,而这种情况的确发生过[7]:在一个 GitHub 著名事故中,包在网络中大约延迟了90秒[8]。这意味着一个应用进程可能发送一个写请求,这个请求可能在一分钟之后租约已经过期的时候才到达存储服务。
即使在良好的网络中,这种情况也会发生。你根本不能对时间作出任何保证,所以无论你使用哪种锁服务,上述代码都不安全。
用 fencing token 让锁安全
这种问题的解决方案非常简单:你需要在每个对存储服务的请求中携带一个 fencing token。在此情况下,一个 fencing token 只是一个客户端获得一次锁时递增的数字(如被锁服务递增)。在下图中说明了这一点:
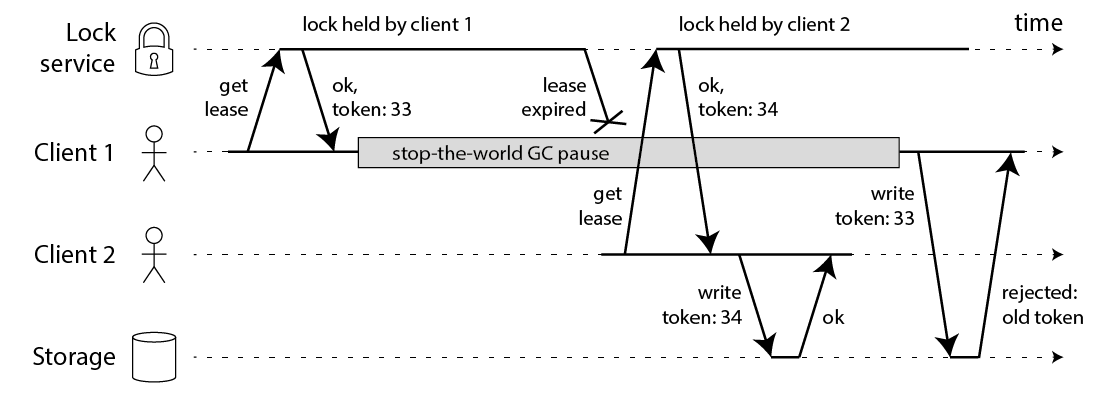
客户端1获得了租约且 token 为33,但是经历了长时间的暂停后租约过期了。客户端2获得了租约,且 token 为34(数字总是递增的),然后携带 token 34发送写请求到存储服务。过了一会儿,客户端1恢复并且携带 token 33发送写请求到存储服务。但是,存储服务知道已经接受过一个更新的 token(34)的请求,所以它拒绝了 token 33这个请求。
这需要存储服务在检查 token 中扮演一个重要的角色,并且拒绝任何旧 token 的所有写请求。只要你掌握了这个窍门就不难了。只要锁服务生成严格的单调递增的 token,那么锁就是安全的。例如,如果你使用 ZooKeeper 作为锁服务,你可以使用 zxid 或 znode 版本号作为 fencing token,这样系统就能获得良好的状态[3]。
但是,这就引出了 Redlock 的第一个大问题:它没有任何生成 fencing token 的功能。该算法不会保证生成每次客户端获得锁时都会增加的数字。这意味着,即使算法在其他方面是完美的,使用它也不安全,因为在一个客户端暂停或网络包延迟的情况下,你无法防止客户端之间的竞争。
在我看来,要改变 Redlock 算法来开始生成 fencing token 并不容易。它使用的唯一随机值没有提供所需的单调性。仅仅在一个 Redis 节点上保留一个计数器是不够的,因为该节点可能会宕机。在多个节点上保持计数器意味着它们不是同步的。你需要一个一致性算法来生成 fencing token(如果给计数器加一很简单的话就好了)。
利用时间来解决一致性问题
Redlock 不能生成 fencing token 这一事实,足以说明不应该在使用锁保证正确性的情况下使用它。但还有一些其他的问题值得讨论。
在学术文献中,与这种算法最贴切系统模型是具有不可靠故障检测器[9]的异步模型。简单地说,这意味着算法对时间没有任何假设:进程可能暂停任意长的时间,数据包在网络中可能随时被延迟,时钟可能会出现不可预知的错误,但是算法需要保证正确性。考虑到我们上面所讨论的,这些都是非常合理的假设。
算法使用时钟的唯一目的是产生超时,以避免在节点宕机时永远等待。但是超时不一定是准确的:仅仅因为一个请求超时了,并不意味着其他节点停机了——也可能是因为网络中有很大的延迟,或者你的本地时钟出错了。当超时由于检测故障时,只能说明可能出了一些问题。(如果可以的话,分布式算法将完全不需要时钟,但这样就不可能达成一致[10]。获取锁就像 CAS 操作,需要达成一致性[11])。
请注意,Redis 使用 gettimeofday (而不是单调时钟)来确定 key 的到期时间。gettimeofday 的手册明确表示,它返回的系统时间会出现不连续的跳跃,它可能突然向前跳了几分钟,甚至向后跳了时间(例如,时钟因与 NTP 服务器相差太大而由 NTP 更新,或者时钟是由管理员手动调整的)。很容易发生 Redis key 的失效比预期快得多或慢得多的情况。
对于异步模型的算法来说,这只是个小事:这些算法通常无需进行任何时间假设[12]就能确保它们的安全性始终保持不变。只有活性属性才依赖于超时或其他故障检测器。简单地说,这意味着即使系统中的时间变化是到处都是(进程暂停、网络延迟、时钟向前和向后跳跃),虽然算法的性能可能会下降,但是算法永远不会做出错误的决定。
然而,Redlock 不是这样的。它的安全性取决于大量有关时间的假设:假设所有 Redis 节点在锁大约到期前的时间里都持有 key;与有效期限相比,网络延迟较小;而且该过程的暂停比有效期短得多。
糟糕的定时打破了 Redlock
让我们看一些示例,以说明 Redlock 对时序假设的依赖。 假设系统有五个 Redis 节点(A,B,C,D 和 E)和两个客户端(1和2)。 如果 Redis 节点之一上的时钟向前跳怎么办?
- 客户端1获得 A、B、C 节点的锁,由于网络问题,无法连接到 D、E。
- 节点 C 上的时钟向前跳转,导致锁过期。
- 客户端2在 C、D、E 节点上获取锁,由于网络问题,无法访问 A 和 B。
- 客户端1和客户端2现在都认为他们持有锁。
如果 C 在将锁持久化到磁盘之前崩溃并立即重新启动,也会发生类似的问题。出于这个原因,Redlock 文档建议延迟重启崩溃节点的时间,至少要达到锁的 TTL。但是,这种重新启动延迟还是依赖于对时间的准确度量,如果时钟跳变,则会失败。
也许你认为时钟跳变是不现实的,因为你对正确配置 NTP 能调正时钟非常有信心。 在这种情况下,让我们看一个进程暂停可能导致算法失败的示例:
- 客户端1请求锁定节点 A、B、C、D、E。
- 当客户机1的响应处于运行状态时,客户机1进入 stop-the-world GC。
- 锁在所有 Redis 节点上失效。
- 客户端2获取节点 A、B、C、D、E 上的锁。
- 客户端1完成 GC,并从 Redis 节点接收到响应,表明它已成功获取了锁(进程暂停后,它们已保存在客户端1的内核网络缓冲区中)。
- 现在,客户端1和2都认为他们持有该锁。
请注意,即使 Redis 是用 C 编写的,没有 GC,但这对我们没有帮助:因为任何客户端可能会遇到 GC 暂停的系统都存在此问题。 你只能通过阻止客户端1在客户端2获得锁之后执行该锁保护下的任何操作来确保安全,例如使用上述方法。
较长的网络延迟会产生与线程暂停相同的效果。 这可能取决于你的 TCP 用户超时时间——如果你让超时时间远短于 Redis TTL,则延迟的网络数据包可能会被忽略,但是我们必须仔细研究 TCP 的实现才能确定。 同时,应用超时,我们又恢复了时间测量的准确性!
Redlock 的同步假设
这些示例表明,只有在使用同步系统模型(即具有以下属性的系统)的情况下,Redlock 才能正常工作:
- 有界的网络延迟(你可以保证数据包始终在一定的最大延迟内到达)
- 有限的进程暂停(换句话说,严格的实时约束,但是通常只能在汽车安全气囊系统等中找到),和
- 有限的时钟错误(祈祷你不会从一个坏的 NTP 服务器上得到你的时间)
请注意,同步模型并不意味着时钟完全同步:这意味着你假设了网络延迟,暂停和时钟漂移的已知的固定上限[12]。 Redlock 假设相对于锁的 TTL 而言,延迟,暂停和时间漂移都很小; 如果计时问题变得与 TTL 一样大,则该算法将失效。
在良好的数据中心环境中,大部分时间都将满足时序假设——这被称为部分同步系统[12]。 但这就够了吗? 一旦违反这些时序假设,Redlock 可能会违反其安全属性,例如在客户端的租约过期之前向另一个客户端授予租约。 如果你依靠锁来确保正确性,那么“大部分时间”是不够的——你需要始终保持正确性。
有大量的证据表明,在大多数实际的系统环境中采用同步系统模型是不安全的[7,8]。不断提醒自己 GitHub 的90秒包延迟事件。看起来 Redlock 不太可能通过 Jepsen 测试。
另一方面,为部分同步的系统模型(或带有故障检测的异步模型)设计的共识算法实际上能够正常工作。 Raft算法,Viewstamped Replication,Zab 和 Paxos 都属于此类。 这种算法必须放弃所有时序假设。 这实际上很难:人们经常认为网络、进程和时钟比实际情况更可靠。但是在混乱的分布式系统现实中,您必须非常谨慎地进行假设。
总结
我认为 Redlock 算法是一个错误的选择,因为它“不伦不类”:对于提高效率的锁来说,它逻辑复杂且代价昂贵,但是对于用于保证正确性的锁来说,它并不是足够安全的。
特别是,该算法对时序和系统时钟进行了危险的假设(尤其是假设一个同步系统具有有限的网络延迟和有限的操作执行时间),如果不满足这些条件,就会违反其安全性。 而且,它缺乏用于生成 fencing token 的功能(可以保护系统免受网络或进程暂停的长时间延迟)。
如果仅在尽力而为的想法上需要锁(作为效率优化,而不是为了确保正确性),我建议坚持使用 Redis 的简单单节点锁算法(在某种条件下调用 set-if-not-exists 来获得锁,原子性地 delete-if-value-matches 来释放锁),并在代码中非常清楚地注释出锁不是准确的,有时可能会失败。不需要设置一个包含五个 Redis 节点的集群。
另一方面,如果你需要使用锁来确保正确性,请不要使用 Redlock。 相反,请使用像 ZooKeeper 这样适当的共识系统(可能是 Curator recipes 的一种实现),至少使用具有合理事务保证的数据库。并且请在锁保护下的所有资源访问上强制使用 fencing tokens。
正如我在开始时所说的,Redis 是一个很好的工具,如果你正确使用它。 以上所有内容都不会削弱 Redis 的功能。 Salvatore 多年来一直致力于该项目,其成功理所应当。但是每种工具都有局限性,了解它们并据此计划很重要。
如果你想了解更多信息,我将在我的书的第8章和第9章中更详细地说明该主题,该书现已在 O’Reilly 的“早期发行版”中提供(以上图表摘自我的书)。要学习如何使用 ZooKeeper,我推荐 Junqueira 和 Reed 的书[3]。 为了更好地介绍分布式系统理论,我推荐 Cachin,Guerraoui 和 Rodrigues 的教科书[13]。
感谢 Kyle Kingsbury,Camille Fournier,Flavio Junqueira 和 Salvatore Sanfilippo 审阅了本文的草稿。 当然,任何错误都是我的。
2016年2月9日更新: Redlock 的原始作者 Salvatore 对本文发表了反驳(另请参见HN讨论)。他提出了一些意见,但我坚持我的结论。如果有时间的话,我可能会在后续帖子中进行详细说明,但请拥有你自己的意见——请查阅以下参考资料,其中许多参考资料都经过了严格的学术同行评审(与我们的任何一篇文章均不同)。
参考
[1] Cary G Gray and David R Cheriton: “Leases: An Efficient Fault-Tolerant Mechanism for Distributed File Cache Consistency,” at 12th ACM Symposium on Operating Systems Principles (SOSP), December 1989. doi:10.1145/74850.74870
[2] Mike Burrows: “The Chubby lock service for loosely-coupled distributed systems,” at 7th USENIX Symposium on Operating System Design and Implementation (OSDI), November 2006.
[3] Flavio P Junqueira and Benjamin Reed: ZooKeeper: Distributed Process Coordination. O’Reilly Media, November 2013. ISBN: 978-1-4493-6130-3
[4] Enis Söztutar: “HBase and HDFS: Understanding filesystem usage in HBase,” at HBaseCon, June 2013.
[5] Todd Lipcon: “Avoiding Full GCs in Apache HBase with MemStore-Local Allocation Buffers: Part 1,” blog.cloudera.com, 24 February 2011.
[6] Martin Thompson: “Java Garbage Collection Distilled,” mechanical-sympathy.blogspot.co.uk, 16 July 2013.
[7] Peter Bailis and Kyle Kingsbury: “The Network is Reliable,” ACM Queue, volume 12, number 7, July 2014. doi:10.1145/2639988.2639988
[8] Mark Imbriaco: “Downtime last Saturday,” github.com, 26 December 2012.
[9] Tushar Deepak Chandra and Sam Toueg: “Unreliable Failure Detectors for Reliable Distributed Systems,” Journal of the ACM, volume 43, number 2, pages 225–267, March 1996. doi:10.1145/226643.226647
[10] Michael J Fischer, Nancy Lynch, and Michael S Paterson: “Impossibility of Distributed Consensus with One Faulty Process,” Journal of the ACM, volume 32, number 2, pages 374–382, April 1985. doi:10.1145/3149.214121
[11] Maurice P Herlihy: “Wait-Free Synchronization,” ACM Transactions on Programming Languages and Systems, volume 13, number 1, pages 124–149, January 1991. doi:10.1145/114005.102808
[12] Cynthia Dwork, Nancy Lynch, and Larry Stockmeyer: “Consensus in the Presence of Partial Synchrony,” Journal of the ACM, volume 35, number 2, pages 288–323, April 1988. doi:10.1145/42282.42283
[13] Christian Cachin, Rachid Guerraoui, and Luís Rodrigues: Introduction to Reliable and Secure Distributed Programming, Second Edition. Springer, February 2011. ISBN: 978-3-642-15259-7, doi:10.1007/978-3-642-15260-3
参见 Hacker News 上的讨论。
部分评论
antirez:读者注意:在文章中使用 Redlock 算法的方式存在错误:获取多数后的最后一步是检查经过的总时间是否已超过锁的 TTL,在这种情况下,客户端不认为锁是有效的。 这使得 Redlock 不受客户端<->锁服务器消息延迟的影响,并且在处理锁保护的资源的出现 GC 暂停时会对锁进行有效性验证,验证之后让所有其他客户端延迟。如果在使用远程锁服务器时:由于在读取之前 socket 暂停,导致“你持有锁”这个来自服务器的响应仍然在内核缓冲区中。这种情况与前者等价。因此,在此文章中,假设在锁定获取阶段出现网络延迟或 GC 暂停是一个错误。
Martin leppmann:你是正确的,我忽略了收到消息后的其他时钟检查。 但是,我相信额外的检查实际上不会改变算法的属性:
应用程序和共享资源(受锁保护的事物)之间的较大网络延迟仍可能导致资源从不再持有锁的应用程序进程接收消息,因此仍然需要保护。
GC 暂停发生在最终时钟检查和资源访问之间时不会被时钟检查捕获。正如我在文章中指出的那样:“请记住,GC 以在任何时间暂停正在运行的线程,包括对你最不利的时间点”。
所有对时钟测量精度的依赖仍然成立。
antirez:你好 Martin,谢谢你的答复。应用程序和共享资源之间的网络延迟,以及检查之后但在进行实际工作之前的 GC 暂停在概念上都与你的“第一个论点”完全相同,即 GC 暂停(或其他暂停)使算法需要增量 token。因此,至于算法本身的安全性,剩下只有对时钟漂移的依赖这一点,这可以从不同的角度来论证。因此恕我直言,当前版本的文章展示了错误的算法实现,没有列举处理共享资源的 GC 暂停的等效性,与获得 token 之后立即 GC 暂停并不相同。